我喜欢把核心内容放开头
此次log.info耗时异常升高,是由于日志量过大(5G甚至以上),并且使用同步阻塞的RollingFileAppender+TimeBasedRollingPolicy,导致log.info一直等待日志文件滚动,造成了异常。解决方式很简单:
- 修改logback.xml里logger配置,准确定义日志打印的包甚至类,控制日志量
- 使用异步非阻塞的Appender,例如:AsyncAppender
- 注意appender-file(即日志打印路径)与rollingPolicy-fileNamePattern中的路径是否一致,这次的异常可能与两个路径不同导致,因为底层在滚动旧日志时使用java.io.File#renameTo,这个方法(linux环境下)在路径不同时会移动文件再重命名,耗时明显增长,尤其在容器环境中两个路径挂载在不同的硬盘上更会拉长时间。
背景
公司使用xxl-job框架实现的分布式任务调度。
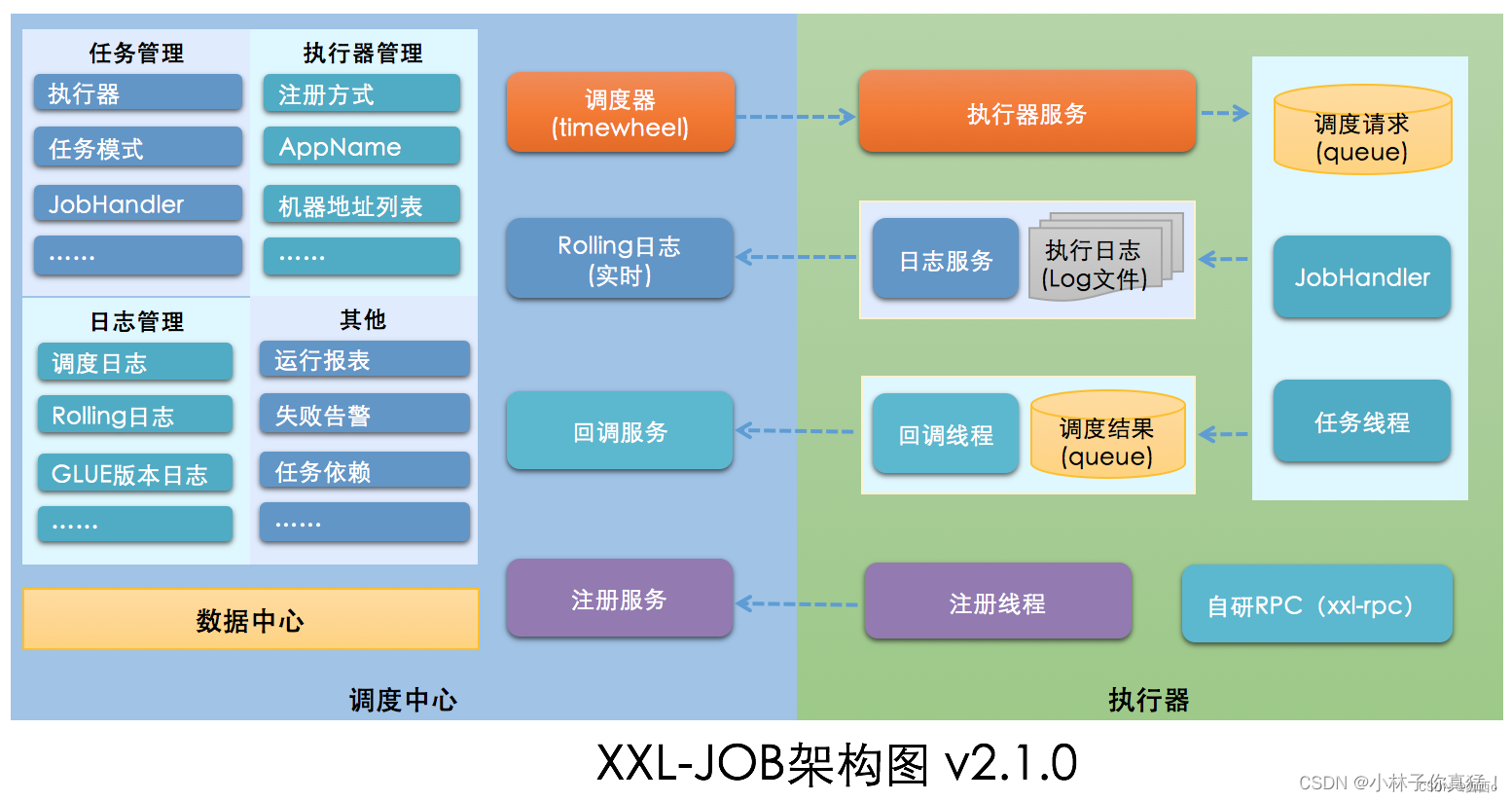
xxl-job主要分两块,一个管理端,若干执行器。管理端将任务派发给执行器执行,调度方式是管理端通过http请求执行器的接口实现调度。
现象
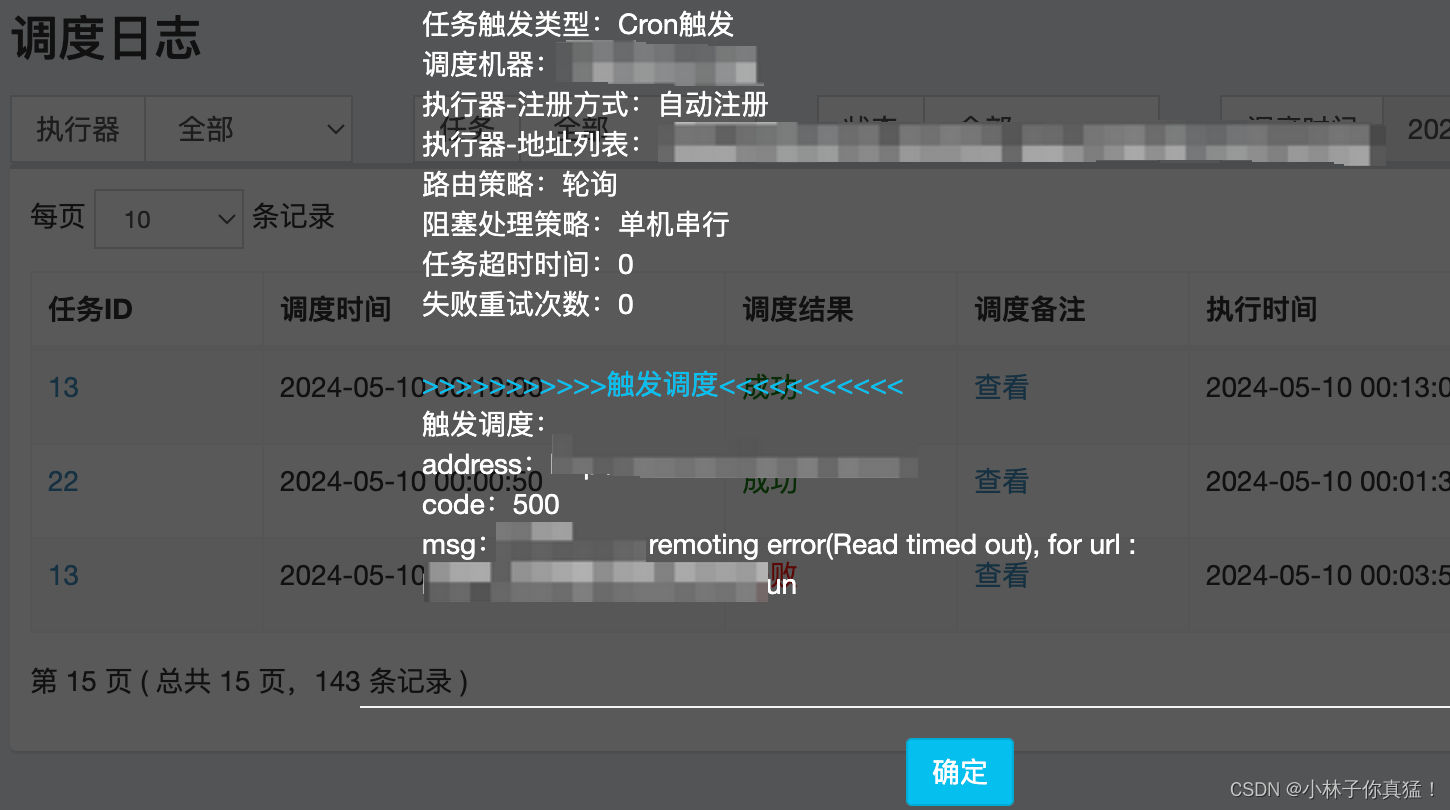
自从一次上线后管理端每天00:00的任务会调度失败,且过了00:00之后调度就恢复了。

调度失败的日志显示是因为接口超时:
源码解析
配置文件加载与本次的异常无关,只是之前没研究过logback相关的源码,所以这次从头看了一下。
小伙伴们应该都知道logback会默认从工程目录中寻找logback.xml配置,并根据配置加载logger等组件。但是什么时候开始加载logback.xml,logback又是如何配置appender与rollingPolicy的呢?
我将断点打在start:65, TimeBasedRollingPolicy (ch.qos.logback.core.rolling) ,沿着堆栈向上查看。
slf4j作为门面框架通过LoggerFactory.getLogger第一次被调用时初始化整个日志框架。
初始化默认日志上下文:
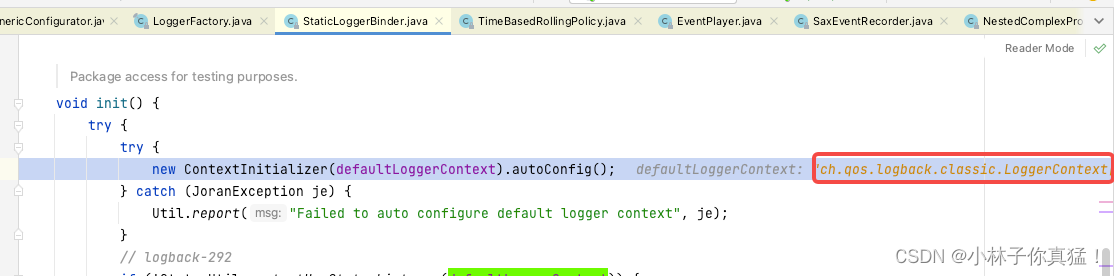
默认为logback.
然后ContextInitializer会在本地找logback配置文件:
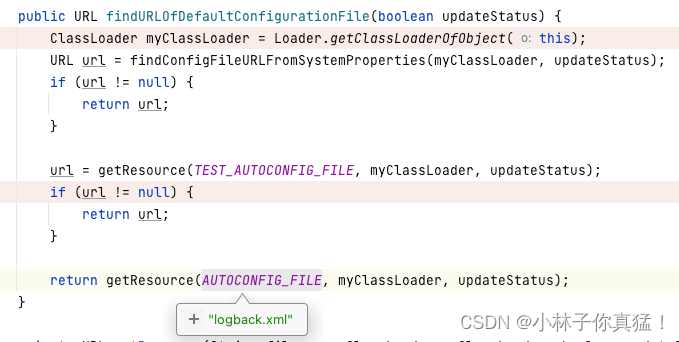
这里可以看到logback.xml的加载由Classloader.getResource获取:
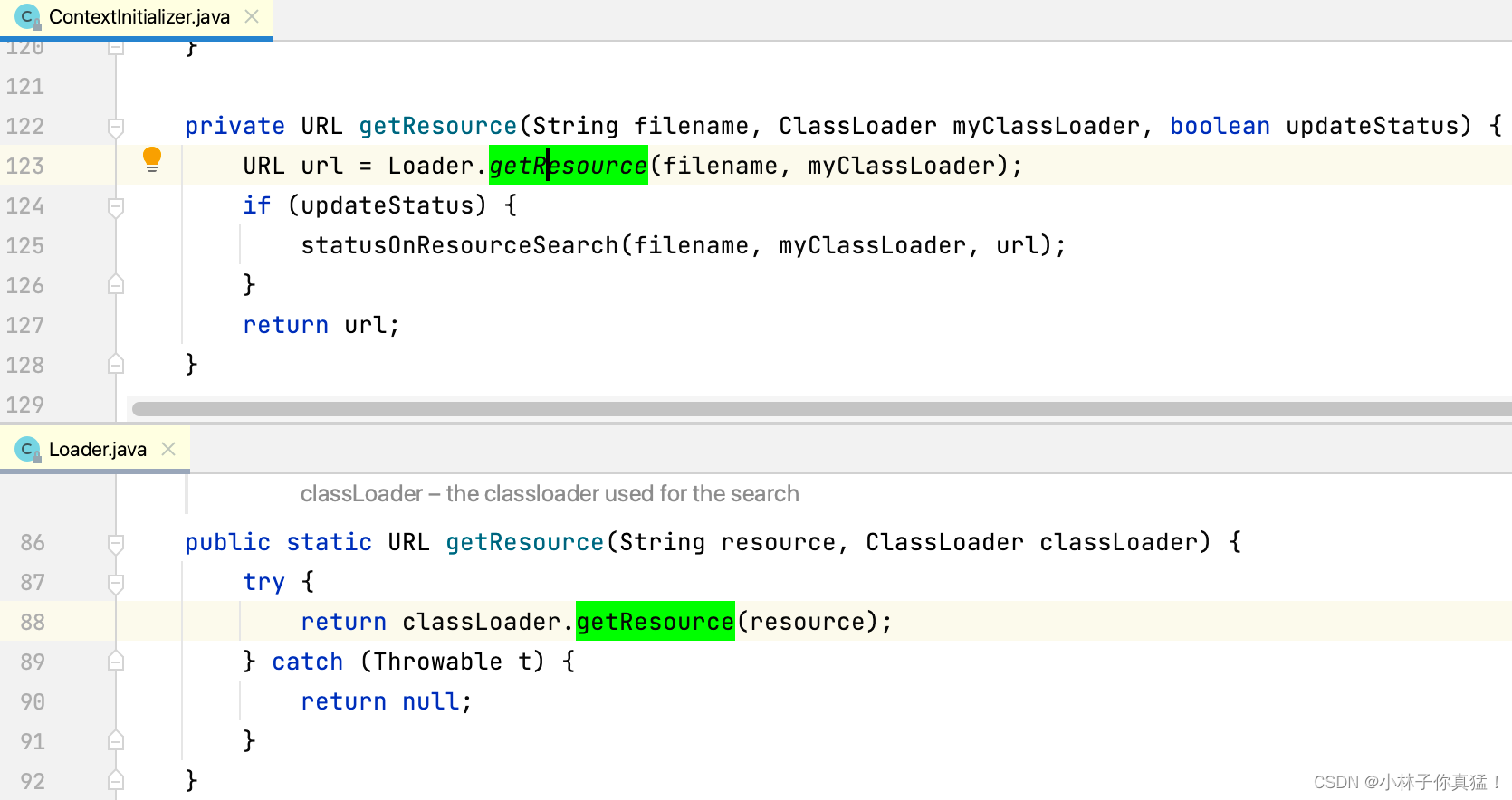
这里引入另一个踩过的坑,如果您使用start.sh等通过java命令启动的项目,需要小心classpath中jar包的顺序,务必将您自己的项目jar放在classpath最前面,否则可能出现由其他jar包中的logback.xml配置日志打印,出现驴唇不对马嘴的日志打印效果。
找到logback.xml之后开始加载配置文件,装配组件:
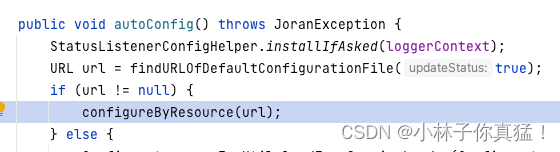

logback选择SAXParser流式处理,xml会被读取成startevent-bodyevent-endevent这样的结构:
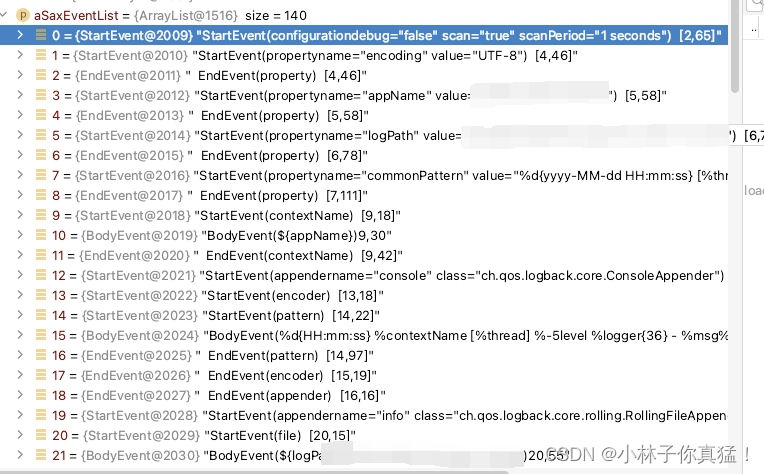
随后根据这些event进行解析
public void play(List<SaxEvent> aSaxEventList) {
eventList = aSaxEventList;
SaxEvent se;
for (currentIndex = 0; currentIndex < eventList.size(); currentIndex++) {
se = eventList.get(currentIndex);
if (se instanceof StartEvent) {
interpreter.startElement((StartEvent) se);
// invoke fireInPlay after startElement processing
interpreter.getInterpretationContext().fireInPlay(se);
}
if (se instanceof BodyEvent) {
// invoke fireInPlay before characters processing
interpreter.getInterpretationContext().fireInPlay(se);
interpreter.characters((BodyEvent) se);
}
if (se instanceof EndEvent) {
// invoke fireInPlay before endElement processing
interpreter.getInterpretationContext().fireInPlay(se);
interpreter.endElement((EndEvent) se);
}
}
}
例如logger的appender、level参数和logger根据name形成的树状结构都是在StartEvent进行设置的。
而appender的file、filter、encoder、rollingPolicy参数都是在bodyevent进行设置的:
public void body(InterpretationContext ec, String body) {
String finalBody = ec.subst(body);
// get the action data object pushed in isApplicable() method call
IADataForBasicProperty actionData = (IADataForBasicProperty) actionDataStack.peek();
switch (actionData.aggregationType) {
case AS_BASIC_PROPERTY:
//这里的setproperty通过反射调用参数对应的setter方法,将参数传递进去
actionData.parentBean.setProperty(actionData.propertyName, finalBody);
break;
case AS_BASIC_PROPERTY_COLLECTION:
actionData.parentBean.addBasicProperty(actionData.propertyName, finalBody);
break;
default:
addError("Unexpected aggregationType " + actionData.aggregationType);
}
}
当然TimeBasedRollingPolicy的fileNamePattern这样设置进来的。
随后到endevent由ch.qos.logback.core.joran.action.NestedComplexPropertyIA.end调用LifeCycle的start方法,这里的nestedcomplexproperty就是配置的TimeBasedRollingPolicy
 TimeBasedRollingPolicy.start方法主要做了以下几件事:
TimeBasedRollingPolicy.start方法主要做了以下几件事:
- 初始化时间相关的配置:它会根据配置(如 fileNamePattern)解析并初始化与时间滚动相关的参数。
- 设置当前活动文件:基于当前时间和配置的文件名模式,start() 方法会计算当前应该使用的日志文件名,并设置该文件为当前活动的日志文件。
- 处理文件压缩:如果配置了文件压缩(如通过 maxHistory 和 totalSizeCap 参数),start() 方法可能还会设置相关的压缩机制,以便在旧文件不再需要时自动压缩它们以节省空间。
- 验证配置
日志打印相信大家经常接触,简单看一下源码。
首先在org.slf4j.LoggerFactory#getLogger时,经过了前面logback.xml配置的解析,会通过ch.qos.logback.classic.LoggerContext#getLogger获取logger,注意方法中的while循环:
@Override
public final Logger getLogger(final String name) {
if (name == null) {
throw new IllegalArgumentException("name argument cannot be null");
}
// if we are asking for the root logger, then let us return it without
// wasting time
if (Logger.ROOT_LOGGER_NAME.equalsIgnoreCase(name)) {
return root;
}
int i = 0;
Logger logger = root;
// check if the desired logger exists, if it does, return it
// without further ado.
Logger childLogger = (Logger) loggerCache.get(name);
// if we have the child, then let us return it without wasting time
if (childLogger != null) {
return childLogger;
}
// if the desired logger does not exist, them create all the loggers
// in between as well (if they don't already exist)
String childName;
while (true) {
int h = LoggerNameUtil.getSeparatorIndexOf(name, i);
if (h == -1) {
childName = name;
} else {
childName = name.substring(0, h);
}
// move i left of the last point
i = h + 1;
synchronized (logger) {
childLogger = logger.getChildByName(childName);
if (childLogger == null) {
childLogger = logger.createChildByName(childName);
loggerCache.put(childName, childLogger);
incSize();
}
}
logger = childLogger;
if (h == -1) {
return childLogger;
}
}
}
我们一般在logback中这样配置一个logger,name为我们的包名,while循环里的LoggerNameUtil.getSeparatorIndexOf(name, i)会将name根据‘.’或‘$’进行切割,组成以root为根logger的logger树:
<logger name="com.abc.xyz" additivity="false" level="info">
<appender-ref ref="info"/>
<appender-ref ref="error"/>
</logger>
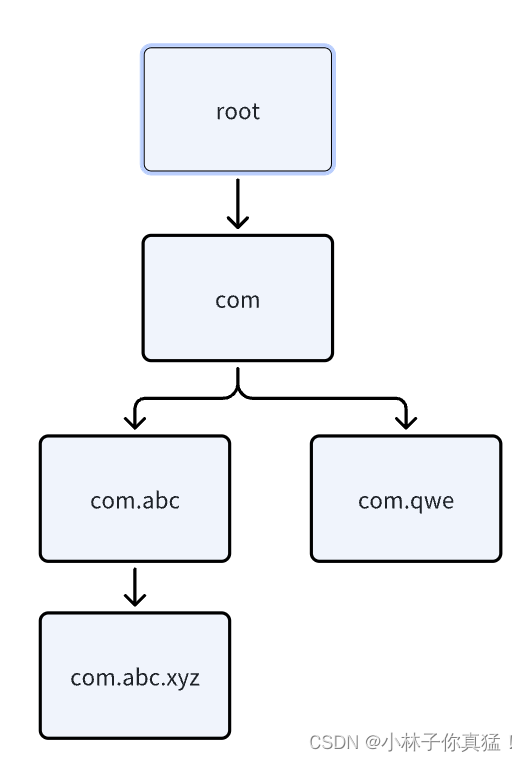
这棵logger树存放在loggerCache中,当我们在类中使用@Slf4j或手写的org.slf4j.LoggerFactory#getLogger获取logger会尝试从loggerCache中获取,没有则新建,并按同样逻辑插入树中。
前期准备总算介绍得差不多了,下面说实际打印
ch.qos.logback.classic.Logger.info调用到ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus
filterAndLog_0_Or3Plus这个方法做两件事:1.过滤日志等级 2.调用appender打印日志
/**
* The next methods are not merged into one because of the time we gain by not
* creating a new Object[] with the params. This reduces the cost of not
* logging by about 20 nanoseconds.
*/
private void filterAndLog_0_Or3Plus(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params,
final Throwable t) {
final FilterReply decision = loggerContext.getTurboFilterChainDecision_0_3OrMore(marker, this, level, msg, params, t);
if (decision == FilterReply.NEUTRAL) {
if (effectiveLevelInt > level.levelInt) {
return;
}
} else if (decision == FilterReply.DENY) {
return;
}
buildLoggingEventAndAppend(localFQCN, marker, level, msg, params, t);
}
可以看出logger会沿树遍历parent:
/**
* Invoke all the appenders of this logger.
*
* @param event
* The event to log
*/
public void callAppenders(ILoggingEvent event) {
int writes = 0;
for (Logger l = this; l != null; l = l.parent) {
writes += l.appendLoopOnAppenders(event);
if (!l.additive) {
break;
}
}
// No appenders in hierarchy
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
}
最终来到目标appender:
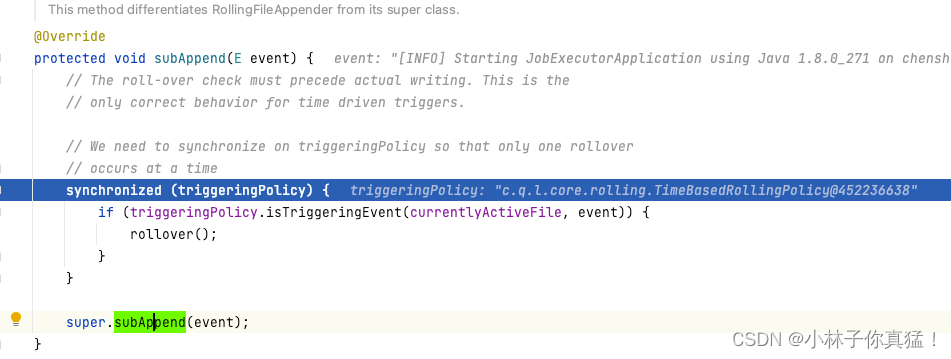
可以看到这里RollingFileAppender处理事件的逻辑,首先锁住triggeringPolicy,当triggeringPolicy判断触发了滚动事件则滚动,最后调用父类向文件中写入日志。
这里就可以看出RollingFileAppender通过同步调用实现日志滚动和日志打印,而正好TimeBasedRollingPolicy被设置为这样:
<fileNamePattern>${logPath}/info.log.%d{yyyy-MM-dd}</fileNamePattern>
也就是每天滚动一次,判断是否滚动的逻辑:
ch.qos.logback.core.rolling.DefaultTimeBasedFileNamingAndTriggeringPolicy#isTriggeringEvent
public boolean isTriggeringEvent(File activeFile, final E event) {
long time = getCurrentTime();
if (time >= nextCheck) {
Date dateOfElapsedPeriod = dateInCurrentPeriod;
addInfo("Elapsed period: " + dateOfElapsedPeriod);
elapsedPeriodsFileName = tbrp.fileNamePatternWithoutCompSuffix.convert(dateOfElapsedPeriod);
setDateInCurrentPeriod(time);
computeNextCheck();
return true;
} else {
return false;
}
}
通过当前时间晚于检查时间点时返回true,而nextCheck则在TimeBasedRollingPolicy#start最后和isTriggeringEvent中确认要滚动后调用computeNextCheck();生成的。
protected void computeNextCheck() {
nextCheck = rc.getNextTriggeringDate(dateInCurrentPeriod).getTime();
}

可以看到这里生成的就是明天的00:00。
1720022400000是一个根据你给出的fileNamePattern中时间表达式计算出的下一个满足条件的时间戳,
也就解释了为什么只有在00:00时log.info变慢。
再来看一下确认要滚动后做了什么
从RollingFileAppender这边看总共三步:
- 停止当前日志输出
- 日志滚动
- 创建新日志文件
/**
* Implemented by delegating most of the rollover work to a rolling policy.
*/
public void rollover() {
lock.lock();
try {
// Note: This method needs to be synchronized because it needs exclusive
// access while it closes and then re-opens the target file.
//
// make sure to close the hereto active log file! Renaming under windows
// does not work for open files.
this.closeOutputStream();
attemptRollover();
attemptOpenFile();
} finally {
lock.unlock();
}
}
TimeBasedRollingPolicy这边日志滚动具体操作:
public void rollover() throws RolloverFailure {
// when rollover is called the elapsed period's file has
// been already closed. This is a working assumption of this method.
String elapsedPeriodsFileName = timeBasedFileNamingAndTriggeringPolicy.getElapsedPeriodsFileName();
String elapsedPeriodStem = FileFilterUtil.afterLastSlash(elapsedPeriodsFileName);
if (compressionMode == CompressionMode.NONE) {
if (getParentsRawFileProperty() != null) {
renameUtil.rename(getParentsRawFileProperty(), elapsedPeriodsFileName);
} // else { nothing to do if CompressionMode == NONE and parentsRawFileProperty == null }
} else {
if (getParentsRawFileProperty() == null) {
compressionFuture = compressor.asyncCompress(elapsedPeriodsFileName, elapsedPeriodsFileName, elapsedPeriodStem);
} else {
compressionFuture = renameRawAndAsyncCompress(elapsedPeriodsFileName, elapsedPeriodStem);
}
}
if (archiveRemover != null) {
Date now = new Date(timeBasedFileNamingAndTriggeringPolicy.getCurrentTime());
this.cleanUpFuture = archiveRemover.cleanAsynchronously(now);
}
}
也是分三步:
- 生成滚动后日志文件名
- 根据压缩策略进行滚动
- 如果设置了maxhistory则删除超出设置的日志
压缩策略CompressionMode是根据fileNamePattern结尾来判断的,一共三种:gz/zip/none
/**
* Given the FileNamePattern string, this method determines the compression
* mode depending on last letters of the fileNamePatternStr. Patterns ending
* with .gz imply GZIP compression, endings with '.zip' imply ZIP compression.
* Otherwise and by default, there is no compression.
*
*/
protected void determineCompressionMode() {
if (fileNamePatternStr.endsWith(".gz")) {
addInfo("Will use gz compression");
compressionMode = CompressionMode.GZ;
} else if (fileNamePatternStr.endsWith(".zip")) {
addInfo("Will use zip compression");
compressionMode = CompressionMode.ZIP;
} else {
addInfo("No compression will be used");
compressionMode = CompressionMode.NONE;
}
}
gz和zip就不解释了,看一下None,当压缩策略为none时会进行重命名:
/**
* A relatively robust file renaming method which in case of failure due to
* src and target being on different volumes, falls back onto
* renaming by copying.
*
* @param src
* @param target
* @throws RolloverFailure
*/
public void rename(String src, String target) throws RolloverFailure {
if (src.equals(target)) {
addWarn("Source and target files are the same [" + src + "]. Skipping.");
return;
}
File srcFile = new File(src);
if (srcFile.exists()) {
File targetFile = new File(target);
createMissingTargetDirsIfNecessary(targetFile);
addInfo("Renaming file [" + srcFile + "] to [" + targetFile + "]");
boolean result = srcFile.renameTo(targetFile);
if (!result) {
addWarn("Failed to rename file [" + srcFile + "] as [" + targetFile + "].");
Boolean areOnDifferentVolumes = areOnDifferentVolumes(srcFile, targetFile);
if (Boolean.TRUE.equals(areOnDifferentVolumes)) {
addWarn("Detected different file systems for source [" + src + "] and target [" + target + "]. Attempting rename by copying.");
renameByCopying(src, target);
return;
} else {
addWarn("Please consider leaving the [file] option of " + RollingFileAppender.class.getSimpleName() + " empty.");
addWarn("See also " + RENAMING_ERROR_URL);
}
}
} else {
throw new RolloverFailure("File [" + src + "] does not exist.");
}
}
最终调用的是java.io.File#renameTo,这个方法(linux环境下)在路径不同时会移动文件再重命名,碰巧这次失误将的配置中路径写错,导致日志路径与滚动路径不同,耗时明显增长。